|
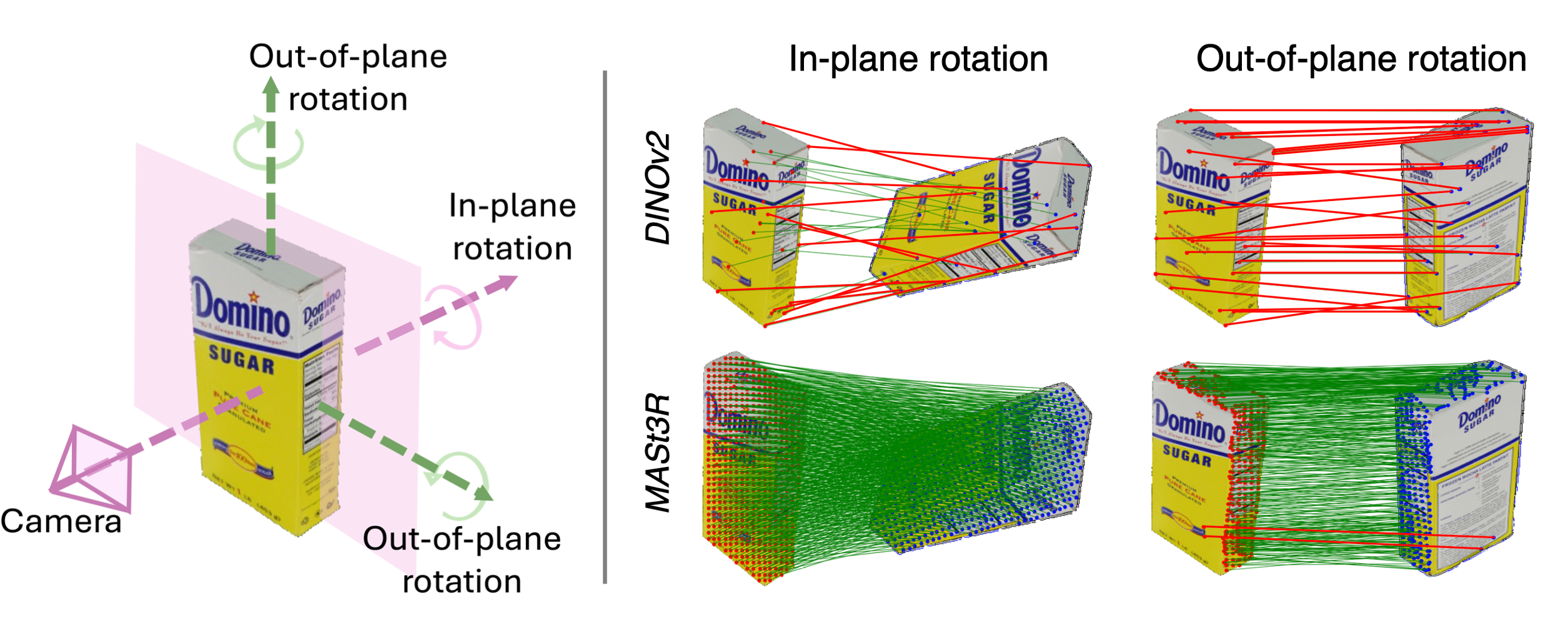
| Foundation 3D models are better equipped to predict 3D-consistent features, which are of significant utility for the pose estimation task. |
|
|
|
|
|
|
|
|
|
| Foundation 3D models are better equipped to predict 3D-consistent features, which are of significant utility for the pose estimation task. |
| Foundation models have significantly reduced the need for task-specific training, while also enhancing generalizability. However, state-of-the-art 6D pose estimators either require further training with pose supervision or neglect advances obtainable from 3D foundation models. The latter is a missed opportunity, since these models are better equipped to predict 3D-consistent features, which are of significant utility for the pose estimation task. To address this gap, we propose Pos3R, a method for estimating the 6D pose of any object from a single RGB image, making extensive use of a 3D reconstruction foundation model and requiring no additional training. We identify template selection as a particular bottleneck for existing methods that is significantly alleviated by the use of a 3D model, which can more easily distinguish between template poses than a 2D model. Despite its simplicity, Pos3R achieves competitive performance on the BOP benchmark across seven diverse datasets, matching or surpassing existing refinement-free methods. Pos3R integrates seamlessly with render-and-compare refinement techniques, demonstrating adaptability for high-precision applications. |
|
|
 |
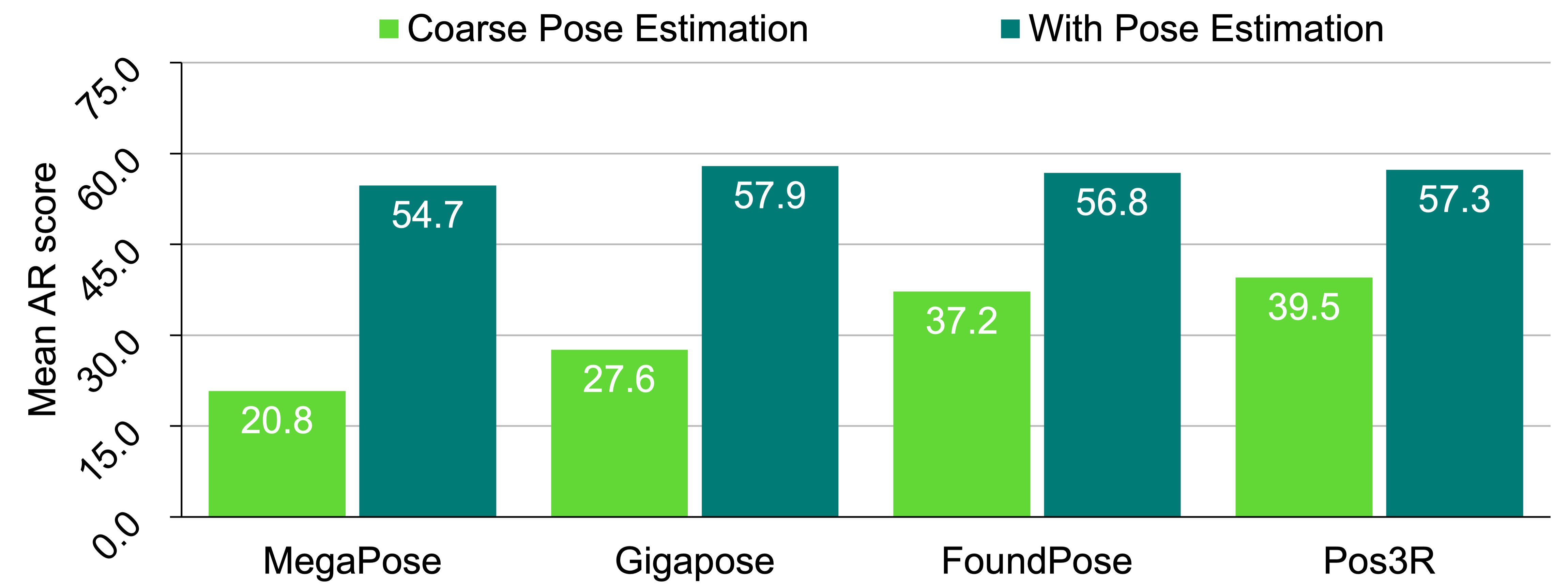
| Pos3R is competitive with the state-of-the-art methods.” |
 |
The blue box indicates ground truth, and green is our estimate.
Pos3R works well under challenging conditions such as clutter, lighting variations, and texture-less surfaces
|
|

However, heavy occlusion remains a limitation
|
|
 |
Deng, W., Campbell, D., Sun, C., Zhang, J., Kanitkar, S., Shaffer, M. E., & Gould, S. Pos3R: 6D Pose Estimation for Unseen Objects Made Easy. In CVPR, 2025. (hosted on [Paper]) |
Acknowledgements |